With the announcement and release of TKG 2.1, it’s about time I publish a post on deploying TKGm 1.6 in my vSphere lab. /sarcasm
If you aren’t familiar with Tanzu Kubernetes Grid (TKG) or, more specifically, TKG Multi-Cloud (TKG-m) then I highly suggest having a read over the official documentation: What is TKG.
In a nutshell, Tanzu Kubernetes Grid is a great solution to deploy and manage Tanzu Kubernetes clusters. TKGs is the variation of TKG that is deeply integrated with vSphere (also known as vSphere with Tanzu), while TKGm can be deployed and managed across one or many clouds, including vSphere. For my own lab, and for this post, I deployed TKGm.
For my own notes and others out there, this will also be a write up introducing TKG and the possible deployment options.
TKGm Overview
Tanzu Kubernetes Grid Multi-Cloud (TKGm) is VMware’s solution to the major problem of not only deploying Kubernetes clusters (in a fast, repeatable manner) but taking that capability to any cloud. All those clusters need additional capabilities (package management) and lifecycling (the Tanzu CLI or, even better, Tanzu Mission Control). What better way than to have this wrapped in a single CLI?
TKGm involves two primary cluster types: Management Clusters and Workload Clusters. There’s also a third - Bootstrap Cluster but it is not part of your day to day.
The TKGm experience starts with the CLI, using it to define and deploy a TKG Management Cluster. This Management Cluster that you deploy is a Kubernetes cluster and is ultimately responsible for managing any Workload Clusters that you deploy. That includes:
- Scale in/scale out operations
- TKG image upgrades
- Workload Cluster node health checks and rebuilds as required
- probably more, but that’s all I’ve done with it so far
Your Workload Clusters are what you connect to and deploy applications into. This is where you and/or your development teams will plumb in their CI/CD tooling to take full advantage of Kubernetes and Tanzu.
Deployment Patterns
With something as flexible as TKGm, you’d imagine there would be any number of ways to deploy and manage those clusters. Well, you imagined correctly. To understand the deployment patterns for TKGm, it helps to understand how TKGm works and deploys Kubernetes clusters.
TKGm uses a local (to your machine) Kubernetes in Docker (KIND) instance to bootstrap a miniature Management cluster. This miniature management cluster is referred to as the Bootstrap cluster. The Bootstrap Cluster is instructed to deploy a formal Management Cluster in the cloud of your choice. It’ll run through the process and spit you out a final kubeconfig file for you to connect to the new management cluster.
This Management Cluster is a Kubernetes cluster, configured in such a way, and with particular cluster resources and definitions, that it is able to deploy and manage workload clusters using Kubernetes principles. The workload clusters themselves are treated as Kubernetes objects that can be lifecycled like any other object.
Interfacing with the management cluster is done via Tanzu CLI, and you can deploy any number of workload clusters using the formal management cluster as the orchestration engine. This provides you a 1:many topology for the deployment and lifecycling of your Kubernetes clusters. As each management cluster is itself a Kubernetes cluster, you are able to create namespaces to house the workload clusters:
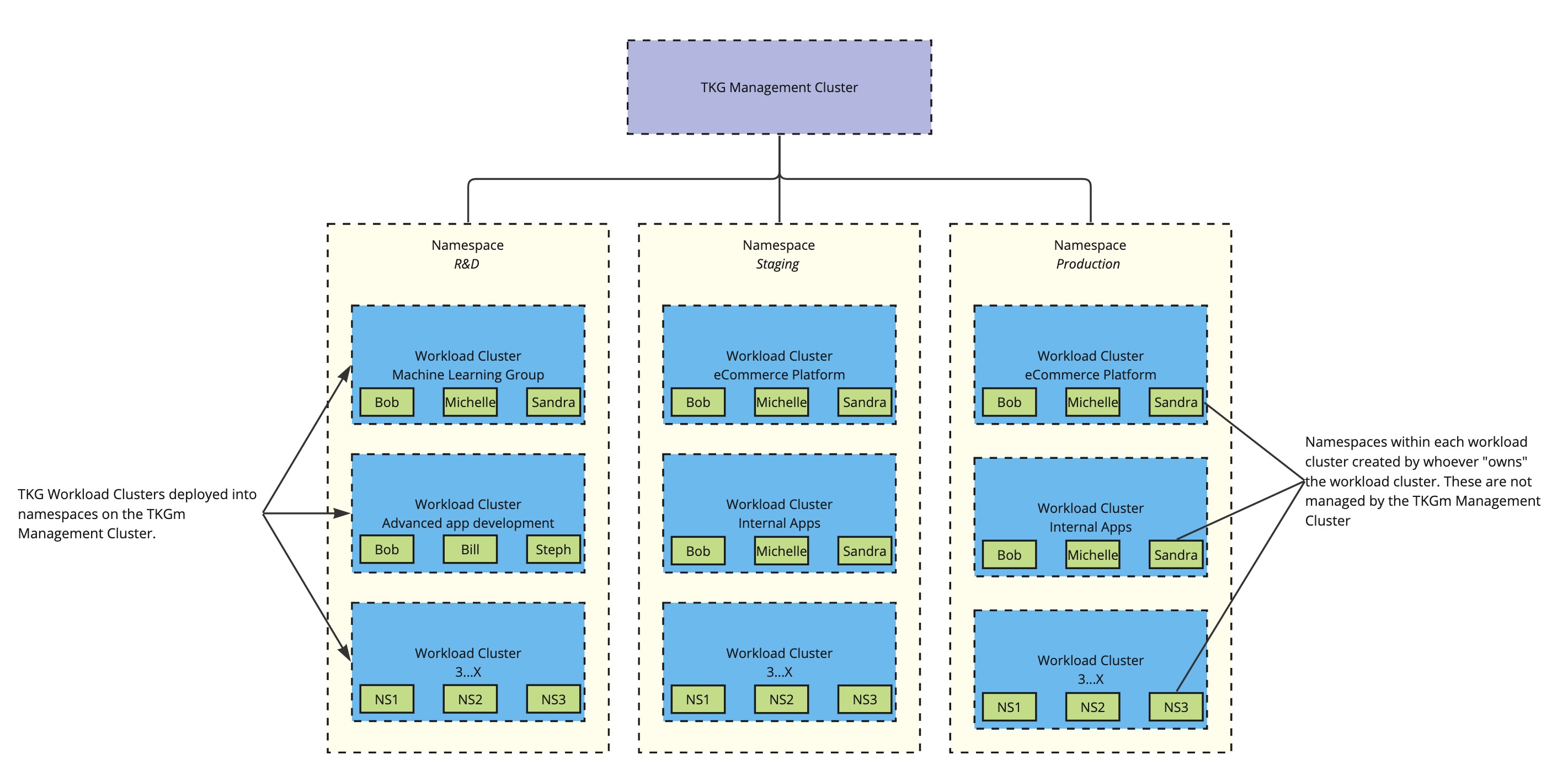
Having a single Management Cluster allows a single administrator, or group of administrators, to manage all workload clusters from a single point. All lifecycling is handled by a single configuration and can be rolled out as you see fit.
However, let’s say you want separate Management Clusters to further separate workload types or environments, you are more than free to do so. Simply run through the new Management Cluster process and you’ll get a new one, along with a new kubeconfig file to connect to it.
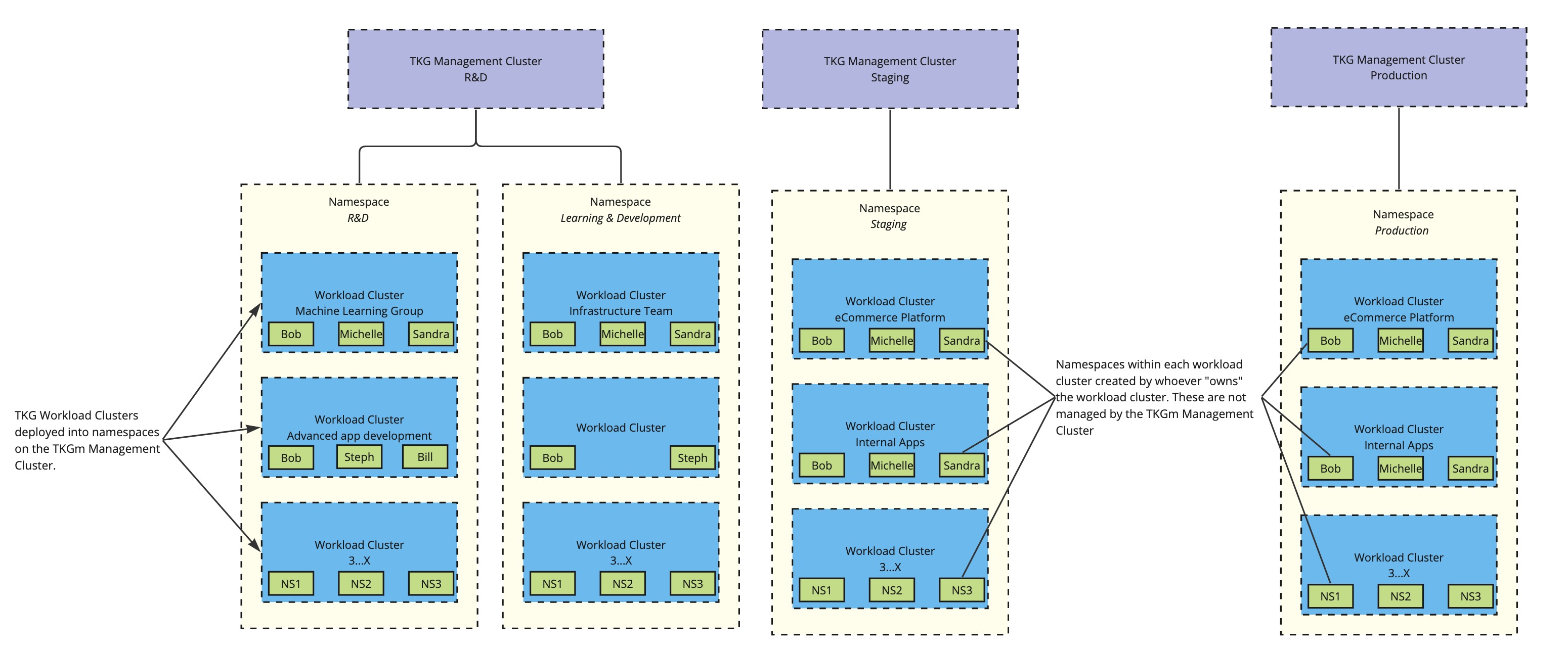
This is an option you’ll see when you need to segregate based on the backing cloud type, or if you have different teams/business units responsible for their own clusters and lifecycling.
With these two designs, you can quickly see how flexible TKGm can be, especially when you want to utilise multiple public and private clouds.
Local Requirements
Before you kick off with TKGm, you’ll need to make sure your local desktop or management/jumpbox server has the appropriate tooling installed.
Note: From the official docs:
- Linux, Windows or Mac machine
- Docker for the Bootstrap KIND cluster to run in. It’s not called Kubernetes in Docker (KIND) for nothing.
- Tanzu CLI for your OS
- kubectl
- VMware Carvel tooling
Environmental Requirements
Of course, you’ll need to make sure the target environment is ready for the awesome power of Tanzu. You’ll need to make sure your networks, firewall and vSphere user accounts are configured correctly.
- The target network for your Management and Workload clusters need to be DHCP enabled. Not the entire subnet, but a range needs to be defined and available for the nodes to receive IPs. Do not make a DHCP range matching your cluster size. When you want to scale out or up, additional nodes are deployed alongside the existing and they will also need IPs (even if temporarily).
- You’ll need to earmark at least one IP per cluster (management and workload) for external management access. This IP is consumed by Kube-Vip for L2 load balancing so you can reach (at least) Cluster API. You’ll need more IPs earmarked for any other LB activities you want to do in your workload clusters.
- If you are planning to deploy applications on the workload clusters that are sourced from public registries (like Docker Hub), the network the workload cluster is in will need internet access.
- Firewall requirements for TKG can be found here: VMware Ports and Protocols.
- vSphere User privileges are detailed here: Permissions for vSphere
Preparation
Reminder, I’m deploying to vSphere. These steps are not here to replace the official docs, but to give you a high-level look at what’s required to get up and running.
- Fetch the TKG images (OVAs) from Customer Connect and import them into vSphere. You’ll need the TKG 1.6.1 images. See the doco for the versions you should be grabbing.
- Generate a SSH keypair and add it to your local store.
Pretty easy overall. The time consuming part is pulling down the TKG images and loading them into vSphere.
Management Cluster Deployment
The official documentation is very detailed when it comes to the deployment process and what will happen in your environment.
There are two options available to you when deploying the management cluster, you can use a fancy UI to provide the information for your management cluster or you can use the CLI and a config file. Frankly, I find the UI handy in this case to not only understand each data required for the deployment, but I can also then understand the context with which the data is required. A great example being the AVI fields in the config file. Guess what? Turns out those aren’t required if you don’t use Avi. Just stick with Kube-vip instead of spinning your tyres trying to understand the fields in the config file.
The beauty of this though is that the UI will spit out a config file for you anyway that you can pull apart and re-use as required, saving time in the future.
So, run the UI: tanzu mc create --ui. This will start the KIND cluster and connect you to the UI wizard for the Management Cluster deployment.
This is probably the easiest part of the whole process. Answer the questions and hit go. Our documentation is detailed and includes screenshots of the process: Deploy Management Clusters with the UI.
By the end of it, you’ll have a management cluster of the node size and count you specified during the wizard. You’ll also be able to download the kubeconfig file and add it to your local kubeconfig (see official k8s docs here).
Workload Cluster
With the management cluster deployed and running you’ll be able to connect to it using kubectl. You won’t need to though. The Tanzu CLI will use your kubeconfig file for any cluster operations, like creating a new workload cluster.
There are some pre-requisites that, if you’re reading this post, I’m assuming you’ve already completed them.
The workload cluster can only be deployed with the config file. There is no UI for this process. However, it is possible to use the management cluster UI wizard to generate a file without having the deployment go through. You can use this generated file, or the one created when you deployed your management cluster. It’s located here: ~/.config/tanzu/tkg/clusterconfigs/ and will have a random file name.
Copy the file, open it, and change the values to what you need for your new workload cluster. Here’s a sample from my lab:
| |
This is a full file, and as you can see, not all fields are required. This is the config file for my management cluster but fields (not values) are identical for a workload cluster. Any caveats, gotchas, callouts, etc should be read about here: Create configuration file
Once you have a config file you’re happy with, issue tanzu cluster create --file /path/to/config/file/config.yaml
Then just sit back and relax.
I’m probably very lucky in that I have a basic setup going into this and do not require any fancy features straight off the bat, but the more advanced features are ones that I’ll delve into later.
Summary
Don’t go into this expecting you won’t have issues. Every issue I’ve seen encountered with TKGm has been the result of a pre-requisite being left out or the wrong TKG images being pulled down. Or firewalls! It’s always firewalls. Or DNS. So read through the ports requirements!
If you’ve never used Kubernetes before, you’re going to bang your head against the wall, mainly at a lot of the terminology being so new to you. Don’t fret though! We have a great resource to get you up to speed: https://kube.academy.
Ultimately, TKG has been fantastic for me in my lab. I’m running several lab-supporting applications in workload clusters, and I’ve even started the process of moving a relatively heavy Wordpress blog (not mine but a family member’s) onto TKG for testing.
It gets even better when you pair it with Velero for backups of your stateful container workloads (which I plan on blogging about) and TKGm’s real power shines when you need to upgrade your clusters! Which, in case you haven’t figured, I’ll be blogging about too!